vi /etc/selinux/config # This file controls the state of SELinux on the system. # SELINUX= can take one of these three values: # enforcing - SELinux security policy is enforced. # permissive - SELinux prints warnings instead of enforcing. # disabled - No SELinux policy is loaded. SELINUX=disabled(需要修改的行) # SELINUXTYPE= can take one of three values: # targeted - Targeted processes are protected, # minimum - Modification of targeted policy. Only selected processes are protected. # mls - Multi Level Security protection. SELINUXTYPE=targeted
[root@localhost ~]# ssh-keygen -t (通过dsa加密方式对秘钥进行加密) Generating public/private dsa key pair. Enter file in which to save the key (/root/.ssh/id_dsa): (注:按回车即可) Created directory '/root/.ssh'. Enter passphrase (empty for no passphrase): (注:按回车即可) Enter same passphrase again: (注:按回车即可) Your identification has been saved in /root/.ssh/id_dsa. (注:生成的私钥文件位置) Your public key has been saved in /root/.ssh/id_dsa.pub. (注:生成的公钥文件位置) The key fingerprint is: SHA256:yCNMfjTp1RKuqVjUh5B8+pTh3ETf3IaWNcVLV7yzYnU root@localhost.localdomain The key's randomart image is: +---[DSA 1024]----+ | ... .o o++| | ooo+.+ o = o+| | o=*== o * + +| | =.+=B.. . . =E| | =oO S . +| | o +.. o . | | . . . . | | | | | +----[SHA256]-----+
[root@localhost ~]# hadoop Usage: hadoop [--config confdir] [COMMAND | CLASSNAME] CLASSNAME run the class named CLASSNAME or where COMMAND is one of: fs run a generic filesystem user client version print the version jar <jar> run a jar file note: please use "yarn jar" to launch YARN applications, not this command. checknative [-a|-h] check native hadoop and compression libraries availability distcp <srcurl> <desturl> copy file or directories recursively archive -archiveName NAME -p <parent path> <src>* <dest> create a hadoop archive classpath prints the class path needed to get the credential interact with credential providers Hadoop jar and the required libraries daemonlog get/set the log level for each daemon trace view and modify Hadoop tracing settings
Most commands print help when invoked w/o parameters.
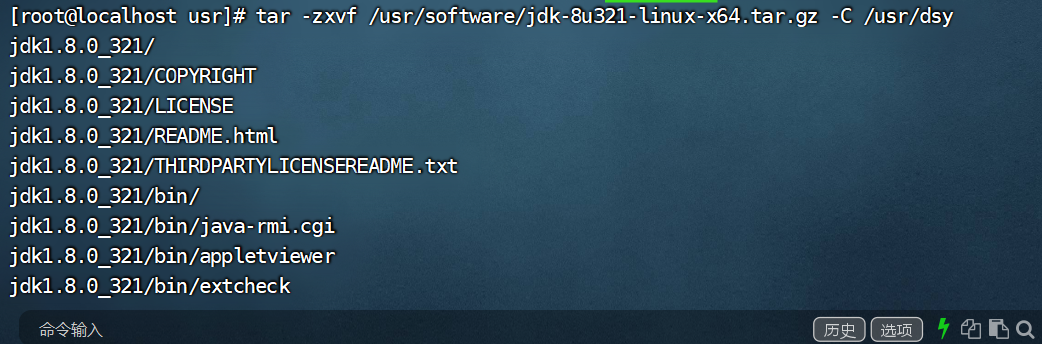
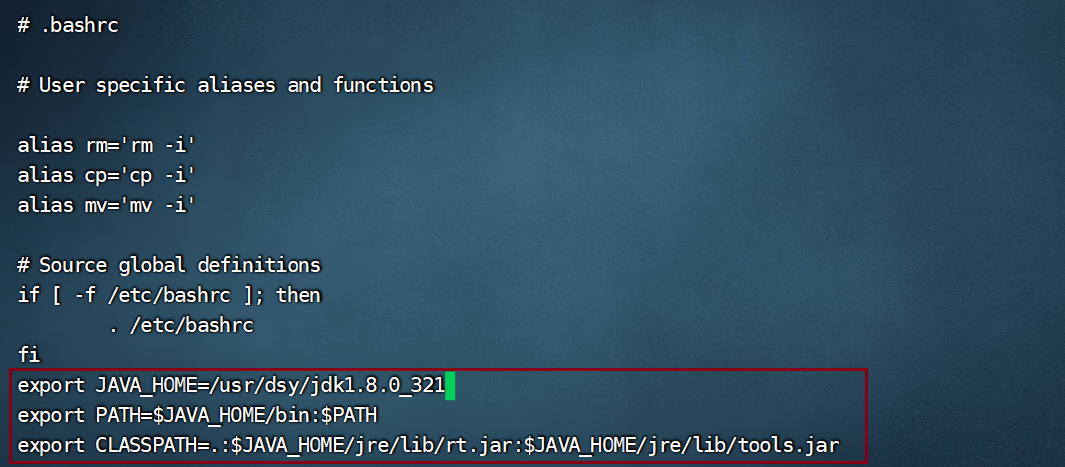
vi /usr/dsy/hadoop-2.7.7/etc/hadoop/hadoop-env.sh (-------------------省略------------------------) # Set Hadoop-specific environment variables here. # The only required environment variable is JAVA_HOME. All others are # optional. When running a distributed configuration it is best to #set JAVA_HOME in this file, so that it is correctly defined on # remote nodes. # The java implementation to use. export JAVA_HOME=${JAVA_HOME}(注:需要对此行内容进行更改,为Hadoop绑定Java运行环境) # The jsvc implementation to use. Jsvc is required to run secure datanodes # that bind to privileged ports to provide authentication of data transfer # protocol. Jsvc is not required if SASL is configured for authentication of # data transfer protocol using non-privileged ports. #export JSVC_HOME=${JSVC_HOME}
vi /usr/dsy/hadoop-2.7.7/etc/hadoop/core-site.xml (-------------------省略------------------------) <!-- Put site-specific property overrides in this file. -->
vi /usr/dsy/hadoop-2.7.7/etc/hadoop/yarn-site.xml (-------------------省略------------------------) <configuration> (注:需要在此处进行相关内容配置) <!-- Site specific YARN configuration properties -->
vi /usr/dsy/hadoop-2.7.7/etc/hadoop/mapred-site.xml (-------------------省略------------------------) <!-- Put site-specific property overrides in this file. -->
(-------------------省略------------------------) Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. -->